
{kind=link}
Can machines understand emotion?

Can you teach an algorithm to recognize the emotional effects of a hurricane? Over the past few years, I’ve been pondering this question. Ross Goodwin, artist and technologist, and I decided to collaborate on if this question could be answered.
This project, How to Train an Algorithm to Understand a Hurricane, was inspired by a talk I gave at Google’s Art and Machine Learning Symposium in Paris back in November 2016. I was born in New Orleans and lived there until I was 1. My family moved to Houston for my dad’s job at that time. My whole family is from Gulf Coast, with grandparents and cousins spread across Louisiana and Mississippi. I’ve been photographing my family since Hurricane Katrina occurred in 2005 because it affected all aspects of my life and my family’s life. As an artist, I was curious about the idea of archiving emotional and traumatic data, and archiving that "data" or photographs, as these events were occurring. What would "post-Katrina" look like 15 years from now, I wondered in 2005. Ross and I hypothesized what visualizing this traumatic data would look like, what it would mean to teach an algorithm to contextualize emotional data about hurricanes. Hurricanes are weather systems and many aspects of hurricanes can be distilled into more quantitative aspects — temperature, time, location, span, length of occurrence, areas affected. But what about the emotional effects of a hurricane — how do you analyze, qualitatively, what was lost and what that feels like? And how do you visualize it?
Over the course of a few months of chatting, we tried to think of a poetic way to build this. This is the first prototype of a much larger project he and I have been working on. This is a large, large project, but as a researcher who works in online harassment, I think a lot about emotional data, and visualizing emotional data, and violent data.
The project, in its current form, has taken the shape of a book and algorithmically generated poetry out of the images and emotional data I’ve created. We’ve turned the book into a simple HTML page here, while we are currently laying out a zine for the work.
This current iteration of the project was inspired by Ross’s Word.Camera, an ongoing project he began in 2015 to automatically and expressively narrate images in real time using machine intelligence. Ross took an old medium format camera, connected to a computer to "see" the world via machine intelligence and output poetry from an algorithm Ross trained. The camera outputted poetry in physical form instantly using a thermal receipt printer. It was reminiscent of the instant quality of Polaroid cameras, but with output in textual form rather than visual. Ross has built web apps as well as a number of physical devices to encapsulate this experience.
Ross wrote a Python wrapper for two spectacular open source Torch scripts by Justin Johnson, DenseCap, and Torch-RNN. Torch is a deep learning framework for the Lua programming language, favored by companies like Facebook and IBM. The Python wrapper enables both Torch scripts to work in tandem to automatically narrate an image.
DenseCap uses convolutional and recurrent neural networks to caption images, and Ross trained his own model on the Visual Genome dataset, using the general guidelines Johnson outlines in his documentation, but with adjustments to increase verbosity.
For the Hurricane project, we augmented Ross’s existing DenseCap model using Amazon’s Mechanical Turk. We asked Mechanical Turk workers go through a few hundred of my photographs with the tagging interface and tag the images with tags such as "car," "tree," and "landscape." This trained our DenseCap convolutional neural network to "descriptively" understand the images. I also tagged several hundred images myself, using "emotional data" tags such as "mother," "Katrina," and "Mississippi." Using the region captions created by these workers, along with those I added myself, the neural network learned how to caption images with my photographs as a reference.
Torch-RNN is a long short-term memory (LSTM) recurrent neural network implementation that can generate text character-by-character after learning statistical patterns from a large body of text. Ross compiled a 40MB data set of (mostly) 20th-century poetry from around the world, and used that corpus to train an LSTM using Torch-RNN.
The stanzas in poems generated by Word.Camera iterate through a range of RNN "temperature" or riskiness values. Lower temperature results are more repetitive and strictly grammatical, while higher temperature results contain more variety but may also contain more errors. Each stanza begins with a DenseCap image caption that the poetic language LSTM then extends into a longer assertion. In other words, the machine uses each caption as a starting point for poetry and then predicts what would come next in a the poem with its understanding of poetry as a reference point.
How To Run It
You don’t need to be a machine learning expert to run this experiment. All you need is some familiarity with the terminal on your computer. Ross tested this software on Ubuntu 16.04. You can try other OS options at your own risk — in theory, it should run on anything that can run Torch and Python, although you will almost certainly run into memory issues if you try to run it on a Raspberry Pi.
Clone the DenseCap and Torch-RNN repos into the main folder, then follow Johnson's instructions to install the dependencies for DenseCap — don't worry about any of the GPU or training stuff, unless you want to use your own models. Thankfully, the dependencies of Torch-RNN are a subset of those required for DenseCap.
Ross built a quick and easy tagging interface and I began tagging the images from an archive of photographs. The archive includes photographs of my family, of the Gulfport, Mississippi, rebuilding, of the first few Mardi Gras in New Orleans post-Katrina, of cityscapes, of mundane moments, of portraits of family members and images of objects that survived the storm and the devastation. All of these images exist as an emotional, personal archive. Some of the tags include things like "location," who owns it, the date it was taken, and then also things like what the image means to me, what I feel, what it represents. Since this is a project about my emotional data, I tried to add as many labels as possible to contextualize these images for an algorithm.
For the book, we selected only 50 images. The rest of the images and training data were important in training the convolutional neural net on what the images "meant" and how the images interacted as a whole, more fuller body of data. This will be the basis of our next project, a larger prototype, that will allow the system to "see" these images and understand the emotional tags I’ve added. What does it mean to take this emotional data, these images of recovery post a hurricane, and try to "explain" that data to a system? We’re engaging in a form of supervised machine learning and generating an emotional corpus out of the ways that I, the photographer and researcher, emotionally contextualize these images for our neural net.
What are the emotional effects of a hurricane, of destruction, and of rebuilding? I’m exploring that in these images. What makes a hurricane a hurricane, what makes rebuilding painful and meaningful? There’s more to these images than "chair", "tree," "grass," there’s what’s left, what was, and what each means to me.
This project has taken a few forms, and under the previous name: What Was This Before it has been shown as a group of images in a gallery in Oakland, California, and built into an interactive piece in Shiraz, Iran.
Some of the images from my "emotional data" archive:
What Was This Before




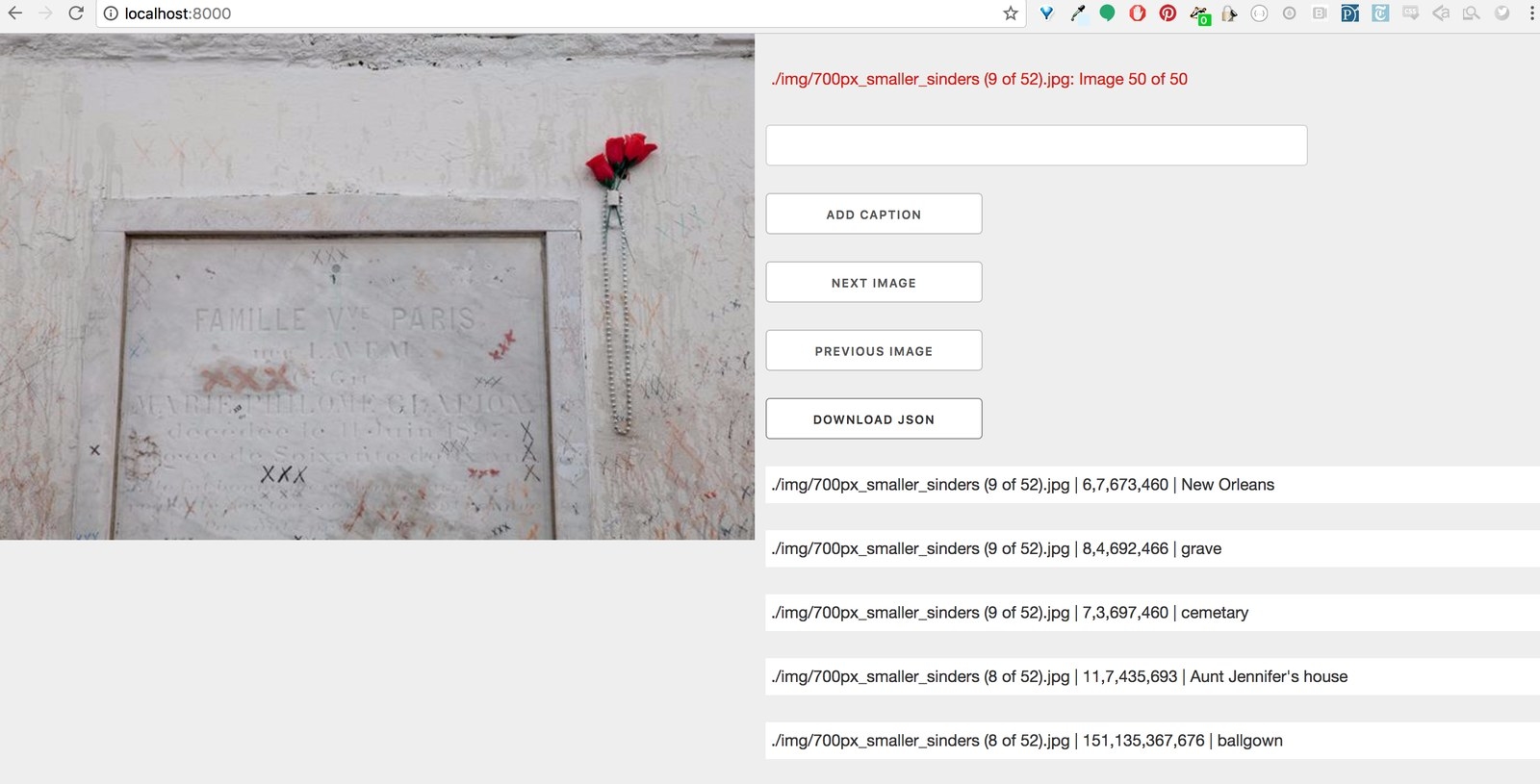
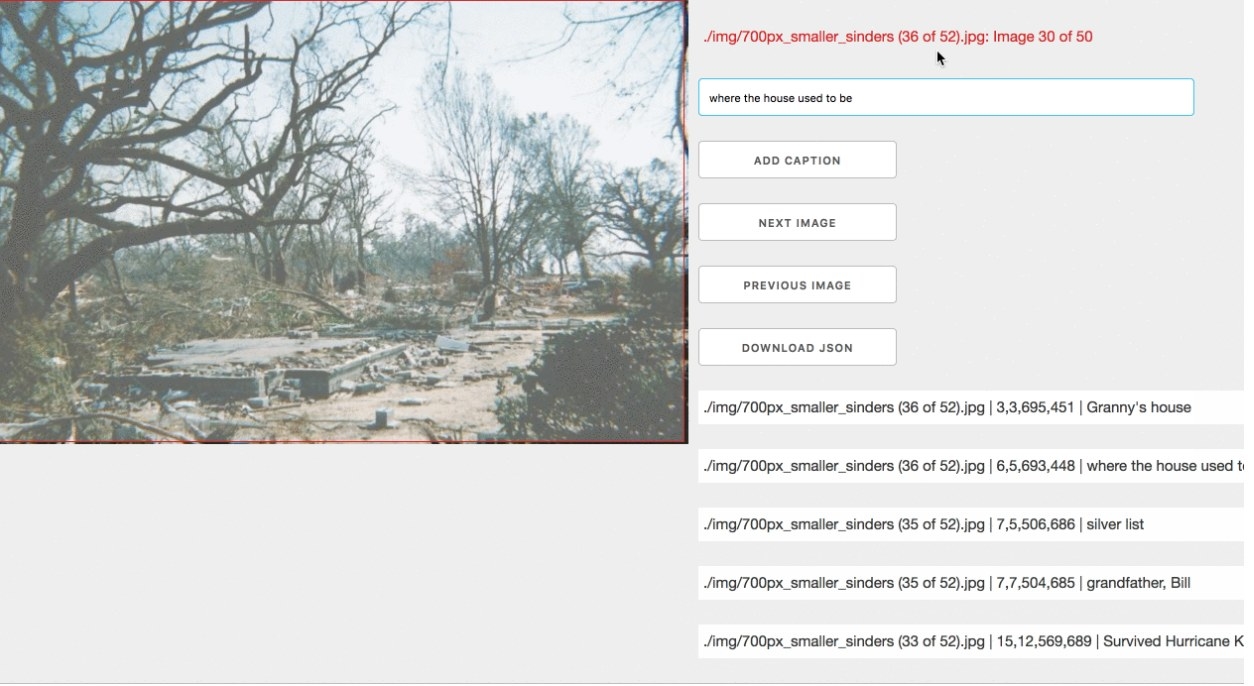
The interface cycles through images in the photo archive, so each can be tagged. I hand tagged hundred of images to train the new version of Word.Camera. I drew selections over each image and tagged what that part of the image "means" or should be labeled as.
This shows, first, my grandmother in the house she moved into after Katrina. I took this photo in 2009. The second photo shows my mother and I at what is left of my grandmother’s two story home and backyard post hurricane Katrina, also in 2009. What’s left is nothing but a field and a foundation. This is the house I learned how to walk in, it’s the house my parents got married in, it’s the house my grandfather built to be hurricane proof with bricks and steel. My grandfather died a few years before Katrina, and now the house is gone, too.
Engaging in supervised machine learning, I wanted to structure the visual data in a way with ‘correct’ output labels. With each labeling, word.camera will train the algorithm to look for similarities between labels. A lot of the similarities will be what, for example, “Gulfport, MS” looks like in my images and how many of the “Gulfport, MS” images also have labels of "mom," "grandmother," and "rebuilding."
Adding multiple labels to each photo allows the algorithm to infer connections between each image. Those connections are a variety of things, from image cropping to similar colors to just what are the most common other labels occurring with certain labels, but all of this training will eventually have the system auto labeling when fed enough data. Could I upload an image of of a sunset over Louis Armstrong Park? What would the system tag that as and what kind of text and related images will it output or suggest? I’m excited to see.