
{kind=link}
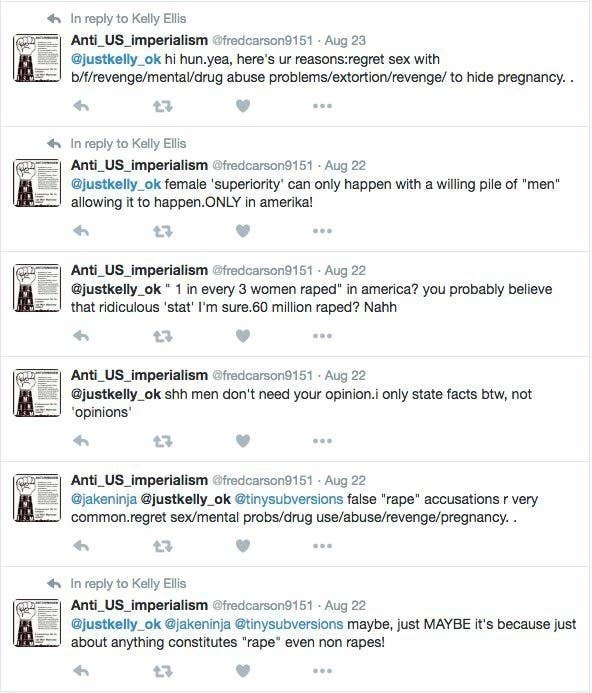
For over a week, Kelly Ellis’s twitter feed was full of rape threats and a stream of accusations coming from a user going by the handle @fredcarson9151. As BuzzFeed News reported in August, Kelly reported the harassment to Twitter multiple times, but Twitter determined that the interactions did not qualify as harassment. Following BuzzFeed’s reporting, the user’s account did get shut down, though Twitter never commented on the episode.
Online harassment can include heated, repeated, antagonized arguments designed to silence or create massive discomfort, rape threats, personal attacks and threats against a person’s safety. Sometimes it comes from total strangers, sometimes from classmates. In some cases harassment has become weaponized, and turned into campaigns that involve thousands of social media users converging on and attacking ordinary, everyday people often over nothing or for no apparent reason. It happens on Twitter, on Facebook, in comments on news articles -- anywhere that people interact online. In 2014 Pew found that 40% of internet users had experienced harassment directed at them online.
It makes sense that online conversations get heated. Human communication is really hard. Conversation is ripe for emotional nuances, and translating emotions into internet space and internet speak can easily be misinterpreted. But there has been a lot of noise around online harassment being simply ‘hurt feelings’ or ‘conversational misunderstandings.’ Deciphering between a Trump supporter and a Clinton voter debating, and engaging in multiple gendered slurs and barbs can be easy or it can be incredibly, incredibly tricky. It all depends upon what the conversation looks like, and the context between the two users. Does the Trump supporter regularly engage with the Clinton voter? Did the Clinton voter antagonize or goad the other? Are the conversations really purposefully hurtful debates that over and over again engage in racist or misogynistic dialogue and continue after someone says, “stop?” A ‘debate’ suddenly has an entirely different meaning if it looks like what I just described. It’s now turned into harassment.
Harassment is more than a simple disagreement. it can be a veiled threat made in referenced memes (looking at you, Pepe) to death threats (which the sender later insists was just a ‘joke’) to rape threats, racist language, or gendered slurs. An apparently innocuous line repeated over and over and over and over again until the recipient feels watched and stalked, because they are. It can be petty, it can be direct. Online harassment is nuanced and hard to define: and that nuance makes it very difficult to confront directly.
I applied to the Open Lab with a provocation- can machine learning help mitigate harassment, specifically in the commenting sections of news publications? Can machine learning identify patterns of conversation and give moderators better data? Harassment is such an expansive action, and involves a multitude of different kinds of language.
Because individual words can seem innocuous out of context, I wanted explore ways to predict the probability of harassment between two different users that don’t depend entirely on the words in a comment or message. Does knowing whether these users have ever interacted before, how old their accounts are, or where they are in the world help a moderator make better judgements? What about patterns in when and where a particular user comments? Can these cues help a computer flag harassment before a moderator even spots it?
I’ve been studying online harassment in social media and political activism in social media for the past five years. I called it my 6 to 11, because I’ve always had a day job. My most recent job was at IBM Watson, where I worked in natural language processing and chat bot software as a user researcher. It was my favorite job, until now. I found out in August I was a part of the 2nd class of Open Lab fellows at BuzzFeed, where I would be the Eyebeam fellow in the group. The ability to finally have the time to explore online harassment and conversation in machine learning is truly a dream come true, especially with the support of BuzzFeed and Eyebeam, an arts and technology center based in New York.
I’ll be doing a lot of things during my fellowship: exploring an anti harassment prototype, testing interfaces for machine learning, creating templates for machine learning, making bots, and developing a series of interventions around surveillance culture. I’ll be collaborating with Angelina Fabbro, a skilled programmer with a background in cognitive science and machine learning, to apply the templates and test out hypotheses. And everything we do will be open source.
I’m focusing my research on journalists and journalism, because I hope that a narrower scope will allow me to make headway on the larger problem. Journalists can often pinpoint why they are receiving harassment or antagonizing comments- it could be because of a particular news article or a story they are covering or even their vertical. There is a lot more contextual data available when trying to solve harassment related to news sites.
As a researcher, I wonder- can we look at user relationships to see how well harassment can be predicted by how far apart users are in an ecosystem?
Ethical Machine Learning
Machine learning is opaque by design but that opacity makes it very hard to examine and critique systems that depend on machine learning. At the same time, it is clear that machine learning is already radically changing product design. Can we make machine learning systems that are transparent? And how do we make machine learning systems ethical?
As a designer and researcher, I care about the ethics of machine learning and especially when machine learning affects users and their data. There are not a lot of machine learning projects at this scale that are also open source. Any system that handles speech and human interactions, and distinguishes ‘good’ speech from ‘bad’ has an obligation to be open about decisions that system makes. I don’t know if it’s possible to build a machine learning system that is completely transparent or even designed for all users but it’s important that machine learning programmers and designers try.
Tempermental ui
There haven’t been many formal conversations about what constitutes ‘good’ design or data visualization for machine learning algorithms and products. Machine learning is a new field and an incredibly technical one, but it is time to start asking design questions.
Transparency in artificial intelligence is hard. Machine learning systems ‘learn’ from user input, so the data they are working from is constantly changing. As a result, the decisions an algorithm makes are also constantly shifting. But how is that shifting landscape conveyed to users who comment within a system and or the admins who maintain the system? Should it be?
This question has been plaguing me for a year: can I create and test interfaces for machine learning applications that are applicable to *all* users, not just technical administrators? Can the interface be informed by nature? Can the interface shift as the data shifts and still remain usable?
As part of my fellowship, I am creating a series of open source machine learning UX templates, with the current name ‘temperamental ui’ to explore creating coherent and transparent design patterns. A template is an easy way to help engineers create more human centered design around any kind of product they create using machine learning with a focus on helping illuminate what the algorithms are doing within the product for users. It’s an effort to help create more transparency around algorithms.
As a researcher who has spent almost two years working in this field and seen an explosion of new companies, new products, and new startups that are using machine learning, this is a trend that is not showing any signs of dying out. Machine learning, with all of its positives and all of its many faults, will change the way in which companies use data and solve problems. I plan on using my research time to explore how machine learning can be used to solve complex problems, and how design can solve some of the inherent problems of machine learning.
All of my research, programming, and testing will be open source (though some information will be anonymized to protect my users and participants). Will my templates ‘work’? I’m excited to find out.

Open Lab for Journalism, Technology, and the Arts is a workshop in BuzzFeed’s San Francisco bureau. We offer fellowships to artists and programmers and storytellers to spend a year making new work in a collaborative environment. Read more about the lab or sign up for our newsletter.