
Earlier this month at BuzzFeed News, we announced we’d be grading this year’s election forecasts. On Monday afternoon, Michigan’s Board of Canvassers finally certified Trump’s win. Now that every state has finally been called — assuming that Jill Stein’s recount effort doesn’t change things — we have the results.
Yes, the polls were wrong. But some forecasters, who typically rely on polls and often combine them with other data to give odds on who will win, were less wrong than others. It doesn’t take fancy math to determine that Nate Silver’s FiveThirtyEight forecasts, although they gave Hillary Clinton better odds than they did Trump, were the least wrong. Not only did he give Trump more than a 1-in-4 chance to win the election, but he also repeatedly defended his forecasts’ bullishness on Trump, for reasons that later proved prescient. Other high-profile forecasts gave Trump small-to-vanishing odds.
To recap, here are the forecasts we examined — listed by the likelihood Trump would beat or tie Clinton in the Electoral College:
FiveThirtyEight — “polls-only” and “polls-plus” (29% and 28%, respectively)
PollSavvy — a “16 y/o high school junior and his stats teacher” (18%)
PredictWise (11%)
Kremp / Slate (10%)
Daily Kos (8%)
The Huffington Post (1.7%)
DeSart and Holbrook (1.4%)
These prognostications are based on how each of the 50 states and the District of Columbia were expected to vote. We can get a better sense — though still imperfect — of the forecasters’ judgment by looking at how they predicted the individual state races.
The basics boil down to this: Which forecasters got the most calls right? Which came closest to the final margins between Clinton and Trump? Which forecasters best balanced confidence and correctness? (For example: Did they give Clinton a 99% chance of winning Michigan or an 80% chance? And were they right?)
The simple approach to judging complicated forecasts
The simplest approach is just to count the number of states each forecaster called correctly. But that misses critical nuance. For example, it doesn’t take into account the difference between 51% odds and 99% odds. Still, it’s an easy place to start.
The Princeton Election Consortium’s Sam Wang guessed more states correctly than anyone else we examined: 46 plus the District of Columbia. Silver’s FiveThirtyEight, and almost every other forecast, got 45 correct. (Wang, unlike the other forecasters, thought Trump would win North Carolina.)
This highlights a paradox: Despite his misplaced hyperconfidence that Clinton would take the White House — giving her a 99% chance — Wang guessed more states “right” than anyone else.
So why did he think Trump had such a small chance of winning? Not only did state polls fail, but most failed in the same way: underestimating Trump. This is called “correlated error.” All forecasters realize that polls aren’t perfect; sometimes they interview the wrong people or weight their responses incorrectly. But part of a forecaster’s job is to estimate how likely — and how extensive — correlated error could be. Many forecasters considered that prospect unlikely, but Nate Silver didn’t.
In his post-election mea culpa, Wang pinpointed this mistake as his forecast’s Achilles' heel. “I did not correctly estimate the size of the correlated error — by a factor of five,” he wrote. “Polls failed, and I amplified that failure.”
A more nuanced approach
Ready for a bit more math? A metric called the Brier score is widely used to quantify forecasters’ accuracy — in elections and beyond. (It’s the main metric we said we’d use for grading. We've posted the data and code behind these calculations on GitHub.)
Brier scores take into account just two things: How likely did the forecaster think something would happen, and did it? Brier scores reward confidence when you’re correct, but penalize confidence when you’re wrong.
Smaller scores are better. Zero is the best possible score — it means you were 100% confident in your predictions, and they all came right. The worst possible score is 1 — you were 100% confident in your predictions, and they all were wrong.
Below are two types of Brier scores for each forecast. The first is weighted by each state’s electoral votes, so that Pennsylvania (20 votes) counts five times as much as New Hampshire (4 votes). The second counts each state equally:
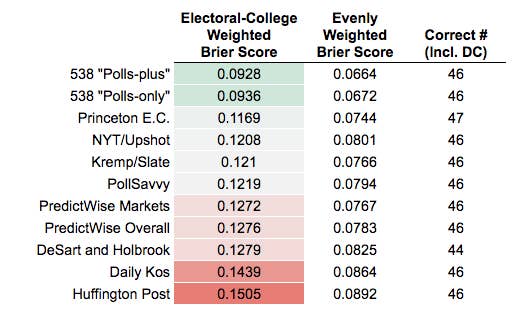
As you can see, FiveThirtyEight’s forecasts scored best. The New York Times and PollSavvy — which gave a Trump presidency the next best chances after FiveThirtyEight — also scored relatively well at the state level. The worst performing forecasts were those from the Huffington Post and Daily Kos, both of which gave near-certain odds to Clinton winning Pennsylvania, Wisconsin, and Michigan. (Shortly after the election, the Huffington Post’s polling editor wrote an article explaining “how we blew it and what we’re doing to prevent a repeat.”)
In the chart above, you’ll notice that all the forecasts scored worse in the “weighted” column than the “unweighted” one. That’s essentially saying: Overall, the forecasters were worse at predicting the outcome in more populous states than in smaller ones. (Side note: Even the most accurate forecasts this year performed worse on the Brier score than any of the high-profile forecasts in 2012, an election with many fewer surprises.)
Another common metric, the logarithmic scoring rule — which places an even greater penalty on misplaced confidence — produces similar rankings at the top and bottom, with a few shifts in the middle of the pack, and penalizes Daily Kos extra for its extreme bullishness on Clinton in Michigan:
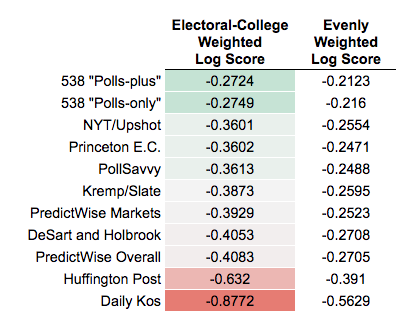
Note: To account for rounding, the log scores above consider all 0% chances to be 0.01% (or 1 in 10,000) chances.
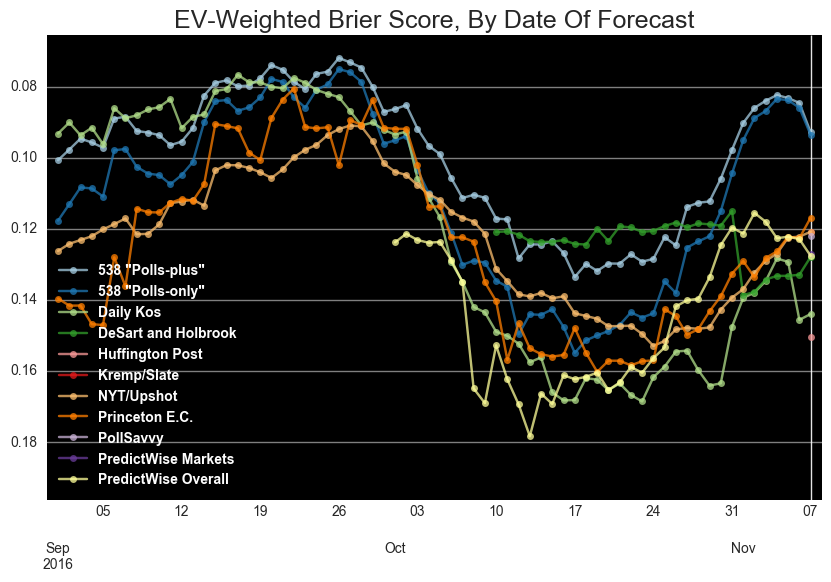
Looking at the forecasters’ predictions over time, you can see FiveThirtyEight’s forecast separate itself from the rest of the pack in early November:
Predicting the vote
It’s clear the polls underrepresented Trump’s support. But which forecast predicted the state-level vote shares most accurately? This is a slightly more difficult question to answer, because the forecasters represented Trump’s expected margin of victory in slightly different ways. We can group the forecasts into two types, with some overlap:
Forecasts that allow calculation of Trump’s expected percentage-point margin of victory over Clinton, among all votes. This group contains FiveThirtyEight, PollSavvy, the New York Times, the Princeton Election Consortium, and the Huffington Post.
Forecasts that allow calculation of Trump’s expected share of the two-party vote (i.e., excluding Johnson, Stein, and McMullin). This group contains FiveThirtyEight, PollSavvy, Daily Kos, Kremp/Slate, and Desart and Holbrook. (PredictWise did not make any vote-share projections.)
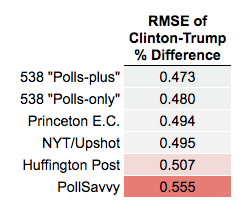
For each presidential state forecast — excluding DC (which some forecasts didn’t estimate) and Utah (where forecasters took different approaches to McMullin’s candidacy) — we calculated the root-mean-square error of the forecasters’ projected margins vs. the actual results. (Some states have yet to fully report their votes, but the current margins for each race appear to be stable. We’ll update the post when the final-final counts are in.)
Among the first group, FiveThirtyEight scored best (smaller numbers are better):
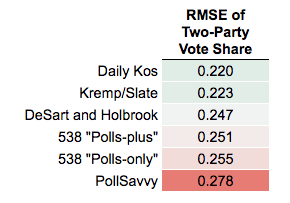
Among the second, FiveThirtyEight did worse, in part because it underestimated Trump’s support in Republican strongholds such as West Virginia and South Dakota to a greater extent than, for example, Daily Kos did:
The Senate Races
Many of the forecasters published predictions for this year’s Senate races, too. The table below shows how they scored on the 32 races we graded. (We didn’t grade California’s Senate race, which pitted two Democrats against each other, or Louisiana’s, which was technically a primary.)
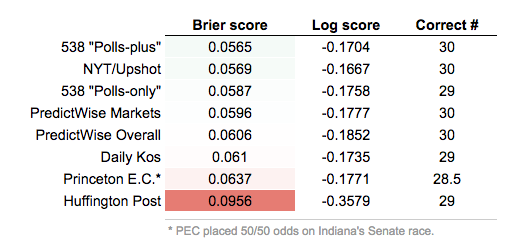
Here, FiveThirtyEight and the New York Times led the pack, though the precise ranking depends on how you score it. According to Brier scores, FiveThirtyEight’s “polls-plus” model edged out the Times. But the logarithmic scoring rule meted out just enough extra punishment against the “polls-plus” — for its overconfidence in Russ Feingold’s chances in Wisconsin — to give the Times the top spot.
That’s it for this year.