
Is Google's Flu Trends (GFT) tracking system a failure of big data?
A new article published this afternoon in Science magazine suggests that Google's much-covered algorithmic Flu Trends model, used to monitor search queries to track the spread of the flu, has routinely failed to accurately predict flu prevalence since it's inception in 2008. While the report is another setback for Google (a 2013 article in the science journal Nature came to a similar conclusion about GFT's accuracy), GFT's failures represent a bigger struggle for data-driven research and threaten to cast a shadow on the broader, much-hyped concept of big data.
In late 2008, Google announced Google Flu Trends to a series of cautiously optimistic early reviews. The New York Times described it as "what appears to be a fruitful marriage of mob behavior and medicine" and many held out hope that Google's algorithm could outperform CDC data models, which have long been held as the standard for flu detection and prediction. Here's a section from Google's blog post announcing Flu Trends in 2008:
It turns out that traditional flu surveillance systems take 1-2 weeks to collect and release surveillance data, but Google search queries can be automatically counted very quickly. By making our flu estimates available each day, Google Flu Trends may provide an early-warning system for outbreaks of influenza.
In reality, Google has continually failed to beat the CDC's model, even with its two-week lag in reporting. According to the report, "GFT also missed by a very large margin in the 2011–2012 flu season and has missed high for 100 out of 108 weeks starting with August 2011." Northeastern University's David Lazer, one of the report's authors, told BuzzFeed that Google's "been missing high the large majority of the time. That's just a fact. When [GFT] was introduced, it had some really bold claims about how close it could get, but we can see there's a big difference in missing CDC predictions by three percentage points and 150 percentage points like it did last year."
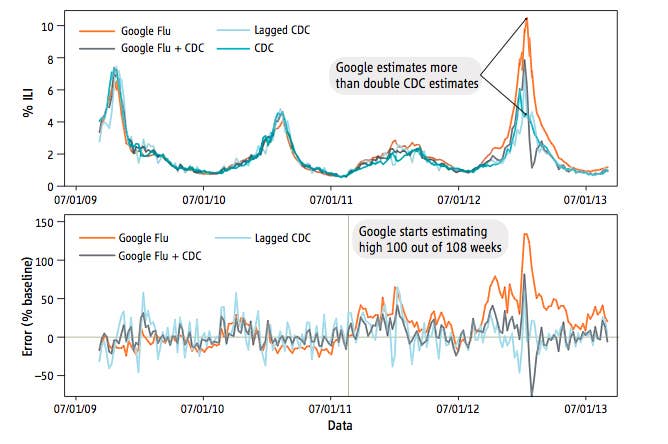
For Lazer and his research team, GFT's problems are symptomatic of the bigger problem of "big data hubris," where readers and researchers alike see big data as a cure-all and an immediate line to the universal truth. Indeed, the most insidious part of the big data movement is the potential for people to believe anything just as long as a Google algorithm or Twitter sampling is attached. "Consider something like Twitter. How much of what's on Twitter is really humans versus bots? When we think of bots, how active are they?" Lazer asks.
"It's easy to fall into a trap with this stuff," Lazer said. "I think of the classic cartoon — nobody on the internet knows you're a dog. If you're trying to measure human opinion and behavior, that's a problem you run into." He notes that, in GFT's case, the data lacks the context to be universally helpful.
"We don't necessarily know what's being reflected when people search for things. We're still making guesses that these could be people or they could be bots," he said. "Even when you search for 'the flu,' you could be searching for that because you have a scholarly interest and you're writing a paper or you could be searching to fix your chimney's flue and you're spelling it wrong. There's no concrete way to differentiate."
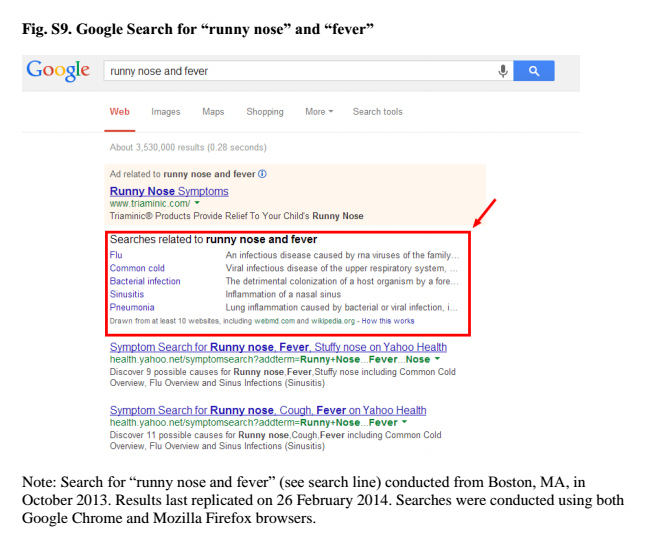
The Science report cites multiple reasons for Google's disappointing results, including changes to Google's search results, which have evolved to produce suggested terms beyond what the user searched for. In February 2012, for example, the search engine began returning potential diagnoses for searches that included symptoms such as "cough," "fever," and "runny nose."
Lazer and his team believe these suggested diagnoses may have contributed to an uptick in "flu" searches. Similarly, the report cites the possibility of outside data manipulation by researchers and argues that, "ironically, the more successful we become at monitoring the behavior of people using these open sources of information, the more tempting it will be to manipulate those signals."
Among Lazer and his team's main concerns is Google's lack of transparency when it comes to sharing not only its data, but its process. "Google should be doing more to make properly anonymized data available and its message transparent," Lazer said. "It's very much a black box right now and you can't fully understand what they've done with their data. Even if you had the data you couldn't replicate what they've done and all good science should be replicable."
With data from the CDC still quite reliable, the stakes haven't yet reached life or death, but the existence of a highly accurate Google model has the potential to save lives by issuing early outbreak warnings. In other words: Google's inaccurate model isn't hurting anyone, it's just not really helping.
While Google's struggles in this space are disappointing, Lazer and others are quick not to discredit the product altogether. Just as it's easy to take large-scale data conclusions as gospel, it's similarly easy to categorize GFT's problems as a failure for the relatively new world of big data as a whole. "I am not surprised that the first model of Google Flu Trends was imperfect," Google data scientist Seth Stephens-Davidowitz told BuzzFeed. "Most first models are. But the idea of using Google to measure health is still really compelling and I think will be proven right in the long term."
Stephens-Davidowitz, who writes frequent New York Times columns using data collected from Google and other platforms, also cautions readers and researchers alike not to read too much into the early successes or the failures of large-scale data projects. "People definitely should not get overly excited about a new tool or overreact when the new tool has a problem," he said.
For his criticisms, Lazer is similarly committed to neither extoll or vilify big data projects and, instead, try to learn from their mistakes.
"The real question of the age right now is 'how do you repurpose all this digital refuse to make it into something truly precious,'" Lazer said. "Sometimes you fail and you're left with a pile of garbage, but sometimes you succeed and turn that garbage into gold."
Lazer seems to hope that exposing the GFT's shortcomings as well as the problems of big data hubris will help move the discussion away from its 'good versus evil' characterization. Big data is neither good nor evil and is only as helpful in the hands of skilled interpreters using ample context and measurement.
"There's huge scientific opportunities around big data that are going to change our understanding of human society. We can see the pulsing dynamics of human society at scale minute by minute, second by second. And that's a completely different data paradigm than we've had for last century," Lazer said. "But we cannot forget basic ideas around measurement and sampling and statistical dependencies that we've known already. Game hasn't changed that much."